


Un logiciel de base de données organise les données pour un stockage fiable, une recherche rapide et une gestion durable.
Le cœur technique : tables, index, verrous et transactions ACID pour garantir cohérence et traçabilité des données.
Choisir entre bases de données relationnelle, NoSQL, distribuées ou cloud dépend du volume de données, des usages et du budget.
Un SGBD apporte SQL, sécurité, optimisation et supervision : de Oracle à MySQL et PostgreSQL.
Le cloud et les modèles DBaaS accélèrent la scalabilité et réduisent la maintenance, sans supprimer les enjeux de conformité.
Les tendances : automatisation par IA, architectures hybrides, et bases de données vectorielles pour les usages IA modernes.
Logiciel de base de données : définition et fonctionnalités clés
Fil conducteur : l’entreprise fictive Atelier Nova (e‑commerce + logistique) modernise ses bases de données pour mieux exploiter ses données, passer au cloud et préparer l’IA.
Définition claire du logiciel de base de données : rôle et fonctionnalités essentielles
Un logiciel de base de données est un système électronique conçu pour le stockage, l’organisation, la gestion, la mise à jour et la recherche efficace d’un ensemble structuré de données. Dans la pratique, il agit comme une “mémoire” métier : commandes, factures, profils, historiques, inventaires, documents et métadonnées deviennent consultables et exploitables en continu.
Ce rôle ne se limite pas à “garder des informations”. Il s’agit de rendre les données fiables, accessibles et réutilisables par des applications : un site web, un ERP, un outil d’analyse, un service mobile ou une API. Sans cette couche, chaque équipe recréerait ses fichiers, ses règles et ses doublons, au prix d’erreurs coûteuses.
Dans Atelier Nova, la première étape consiste à unifier les données de ventes, de stocks et de transport. La base de données devient le point d’ancrage : une commande passée sur le site doit se retrouver en préparation d’expédition, puis en facturation, sans ressaisie ni confusion d’identifiants.
Les fonctionnalités essentielles s’articulent autour de quatre promesses : centralisation (une source de vérité), structuration (schémas, règles et contraintes), accès contrôlé (droits et audit) et rapidité (réponses en millisecondes pour des milliers de requêtes). Un bon outil ne se juge pas seulement à sa richesse, mais à sa capacité à protéger la qualité des données au quotidien.
On distingue souvent la base de données (l’ensemble organisé de données) et le logiciel qui permet de l’opérer, typiquement un SGBD. Cette séparation aide à comprendre l’écosystème : des applications consomment des données ; le SGBD impose les règles ; la base de données matérialise l’information et son historique.
À mesure que l’entreprise grandit, le besoin évolue : on n’attend plus seulement un stockage stable, mais une gestion fine des accès, des sauvegardes, et des performances. C’est là que commence la question suivante : comment, à l’intérieur, une base de données organise-t-elle réellement les données ?

Fonctionnement interne d’une base de données : tables, enregistrements et transactions ACID
Le fonctionnement interne d’une base de données repose sur une structure qui transforme des données brutes en objets consultables. Dans une approche courante, les données sont découpées en tables, chaque table décrivant un sujet : clients, produits, commandes, paiements. Chaque ligne représente un enregistrement, et chaque colonne un champ avec un type (texte, date, nombre, booléen).
Quand Atelier Nova ajoute une commande, l’enregistrement “commande” pointe vers un client et des lignes de commande. Cette organisation permet de limiter la duplication de données : un client n’est pas réécrit à chaque achat. Ce principe de structuration rend la gestion plus sûre et l’exploitation plus cohérente.
Pour accélérer les recherches, un élément clé apparaît : les index. Un index est une structure auxiliaire qui évite de parcourir toutes les lignes pour répondre à une question comme “toutes les commandes du jour” ou “tous les clients d’une ville”. Bien choisis, les index réduisent le temps des requêtes et stabilisent l’expérience des utilisateurs quand la volumétrie de données explose.
Mais la vitesse ne suffit pas : il faut garantir la fiabilité lorsque plusieurs opérations s’exécutent en même temps. C’est le domaine des transactions, régies par le modèle ACID : atomicité, cohérence, isolement, durabilité. L’atomicité signifie qu’une action complexe (débit, écriture, mise à jour d’un stock) se fait entièrement ou pas du tout.
La cohérence impose que les règles métier restent vraies : un stock ne passe pas à une valeur négative si la politique l’interdit. L’isolement empêche qu’un utilisateur voie un état intermédiaire incohérent pendant qu’un autre valide son panier. Enfin, la durabilité garantit qu’une opération confirmée survit à une panne, grâce aux journaux et à l’écriture durable sur disque.
Dans un pic de ventes, Atelier Nova traite des paniers simultanés. Sans transactions ACID, deux achats pourraient réserver le même dernier article. Avec une mécanique robuste, la base de données séquence et verrouille ce qui doit l’être, ou utilise des techniques de contrôle de concurrence. L’insight à retenir : la confiance dans les données naît autant de la structure que des garanties d’exécution.
Les types de bases de données : relationnelles, NoSQL et architectures spécialisées
Il n’existe pas une seule manière d’organiser les données. Les bases de données se déclinent en familles, chacune adaptée à un type de données, de charge de travail et de contraintes de gestion. Le choix d’une technologie revient souvent à arbitrer entre rigidité utile (schéma strict), flexibilité (schéma variable), latence, coûts et tolérance aux pannes.
Dans le même SI, la cohabitation est fréquente : une base de données relationnelle pour la facturation, des bases de données NoSQL pour les événements applicatifs, et un moteur analytique pour l’agrégation. Cette complémentarité évite de forcer toutes les données dans un modèle unique.
Bases relationnelles, hiérarchiques et en réseau : principes et usages
Les bases de données relationnelles dominent les opérations quotidiennes : elles s’appuient sur des tables liées par des clés, avec des contraintes garantissant l’intégrité. Elles brillent quand les données sont fortement structurées et qu’on attend des transactions fiables, comme la comptabilité, la commande, ou la paie.
Des acteurs comme Oracle, MySQL et PostgreSQL incarnent cette tradition, chacun avec ses priorités : robustesse entreprise pour Oracle, simplicité et diffusion massive pour MySQL, puissance SQL et extensibilité pour PostgreSQL. Pour Atelier Nova, une base relationnelle stabilise la facturation, car la moindre incohérence de données se paie en litiges.
Les modèles hiérarchiques et en réseau sont plus anciens historiquement, mais utiles pour comprendre l’évolution. Le hiérarchique organise les données en arbre (parent/enfant), performant quand les parcours sont prévisibles. Le modèle en réseau généralise les liens, autorisant plusieurs parents : un ancêtre conceptuel des graphes modernes.
Dans certains secteurs, des systèmes hérités subsistent, notamment là où la gestion des dossiers a été industrialisée très tôt. La leçon est culturelle autant que technique : les données survivent aux modes, et les bases de données doivent souvent composer avec l’existant pour limiter les risques.
Bases NoSQL : clés-valeurs, documents, colonnes et graphes expliqués
Les bases de données NoSQL répondent au besoin de flexibilité et d’échelle. Elles acceptent des données semi-structurées, des champs optionnels, des formats évolutifs, et privilégient parfois la disponibilité à la rigidité du schéma. Cela ne veut pas dire “sans règles”, mais “sans la contrainte du relationnel partout”.
Le modèle clé-valeur stocke des paires simples, idéal pour sessions, paniers temporaires, ou caches. Les données se lisent vite, et l’architecture s’étend facilement. Le modèle document, illustré par MongoDB, conserve des objets proches du JSON, pratique pour des profils clients dont les attributs varient selon le pays ou le canal.
Les bases de données orientées colonnes (comme Cassandra) optimisent l’écriture et la lecture à grande échelle sur des séries d’événements. Elles sont pertinentes pour les données de logs, IoT, ou suivi d’activité, lorsque le volume rend la gestion relationnelle coûteuse. Enfin, les graphes (comme Neo4j) représentent les relations entre entités, précieux pour fraude, recommandations ou cartographie d’un réseau de dépendances.
Chez Atelier Nova, un flux d’événements “clic, ajout au panier, paiement, expédition” alimente une approche NoSQL pour conserver des données à haut débit. La facturation reste relationnelle, tandis que la personnalisation du site profite de documents plus souples. L’insight : une stratégie de bases de données se construit par usage, pas par doctrine.
Bases distribuées et cloud : adaptation à la gestion moderne des données
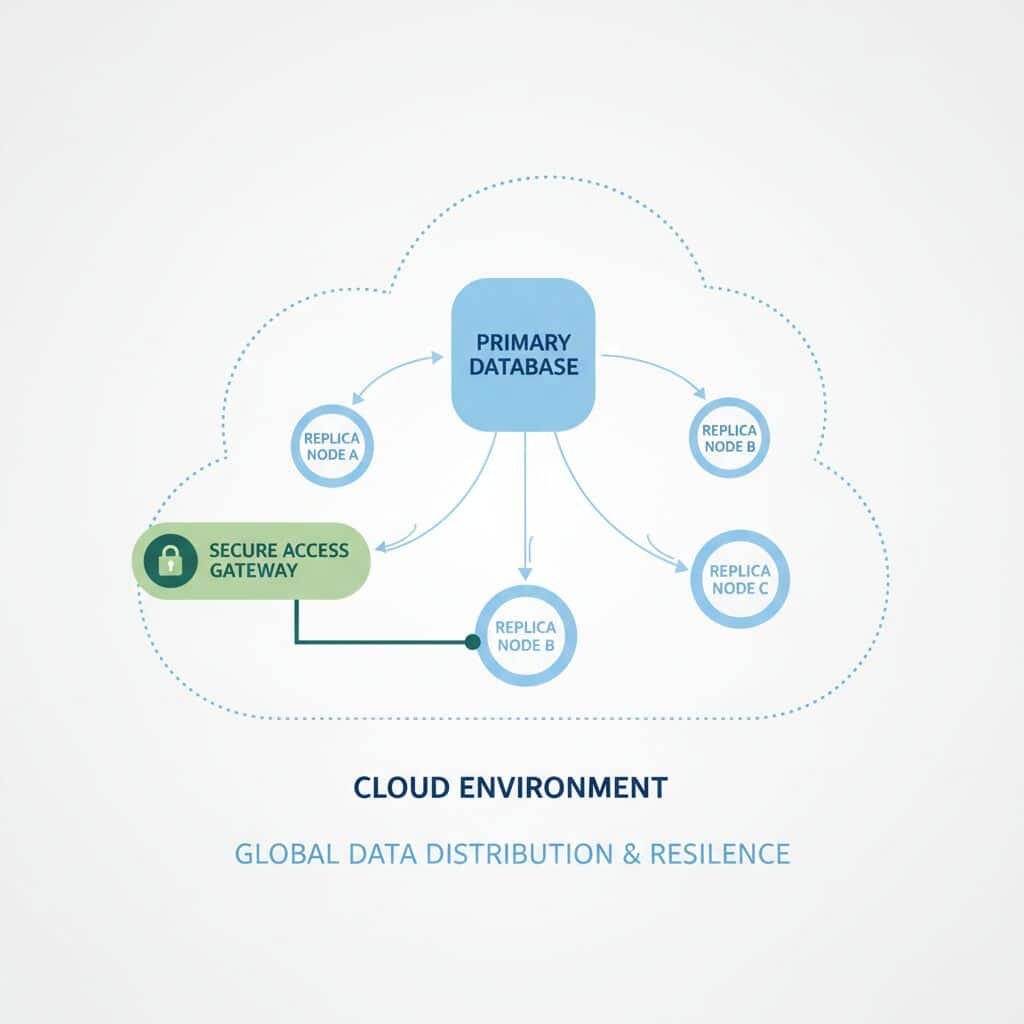
Les architectures distribuées répartissent les données sur plusieurs nœuds pour améliorer la résilience et la capacité. Réplication, partitionnement et consensus deviennent des concepts quotidiens : si un serveur tombe, d’autres continuent à servir les requêtes. Ce choix est guidé par la géographie des utilisateurs, la tolérance aux pannes et la nécessité de traiter des volumes en croissance.
Le cloud amplifie cette logique. Au lieu d’acheter des machines, on provisionne des ressources, souvent en quelques minutes. La gestion de la capacité se transforme : on dimensionne pour les pics, on réduit après, et on paie selon l’usage. La scalabilité devient un levier business, pas seulement un sujet d’infrastructure.
Pour Atelier Nova, vendre à l’international impose de rapprocher certaines données des zones de trafic. Une architecture distribuée dans le cloud limite la latence, tout en conservant des règles de système et de conformité. C’est un équilibre : plus de puissance, mais une complexité de gouvernance plus exigeante.
Système de gestion de bases de données (SGBD) : fonctions, commandes SQL et performances
Un SGBD est le système logiciel qui permet d’interagir avec des bases de données : créer des structures, contrôler les accès, exécuter des requêtes, gérer la concurrence et assurer les sauvegardes. Sans SGBD, la gestion serait artisanale et risquée, car chaque application manipulerait directement les fichiers de stockage.
Les fonctions clés couvrent l’administration, l’optimisation et l’observabilité : plans d’exécution, statistiques, indexation, cache mémoire, journalisation, restauration. Quand une base de données ralentit, ce n’est pas seulement “le serveur” : le SGBD doit expliquer quelles données sont lues, comment elles sont jointes, et pourquoi une requête dérive.
Sur le marché, Oracle reste une référence pour les environnements critiques, notamment via ses outils de tuning et ses mécanismes de haute disponibilité. MySQL est très présent dans les applications web, apprécié pour sa simplicité opérationnelle et son écosystème. PostgreSQL attire les équipes qui veulent un SQL riche, des extensions, et une excellente rigueur sur les données. Dans l’analytique massif, Teradata a marqué l’histoire des entrepôts de données en entreprise.
Manipulation des données avec SQL : SELECT, INSERT, UPDATE et DELETE
Le langage SQL est la grammaire la plus répandue pour interroger et modifier des données dans des bases de données relationnelles. Il sert à exprimer des besoins métiers : “trouver”, “ajouter”, “corriger”, “retirer”. Cette simplicité apparente masque une puissance redoutable dès qu’on joint plusieurs tables.
SELECT extrait des données selon des filtres, tris et agrégations. INSERT crée de nouvelles lignes, UPDATE modifie des champs existants, et DELETE supprime des enregistrements. Dans Atelier Nova, une page “suivi de commande” combine des données de commande, d’expédition et de paiement : une seule requête SQL peut assembler l’ensemble si le modèle est cohérent.
Les bonnes pratiques consistent à écrire des requêtes lisibles, à limiter les lectures inutiles et à utiliser des index alignés sur les accès réels. Le SGBD calcule des plans d’exécution : s’il choisit un parcours inefficace, la charge CPU monte et les temps de réponse se dégradent, avec un impact immédiat sur les utilisateurs.
Au-delà des commandes, SQL s’inscrit dans un système de droits : on n’accorde pas les mêmes permissions à un outil de BI, à une application web ou à un opérateur. L’insight final : le langage SQL est un contrat entre intention métier et mécanique d’exécution, et il faut soigner les deux.
Sécurisation et optimisation des bases via les SGBD populaires
La sécurité dans les bases de données s’appuie sur l’authentification, l’autorisation, le chiffrement et l’audit. Dans un SGBD moderne, on trace qui lit quelles données, quand, depuis quel service. On segmente les environnements (dev, test, prod) et on limite l’exposition réseau.
Sur l’optimisation, les leviers sont concrets : index bien pensés, partitionnement, caches, statistiques à jour, et ajustement des paramètres. Oracle est connu pour ses outils d’analyse des plans et ses options avancées. MySQL se prête bien à une optimisation progressive, via des index ciblés et une discipline sur les schémas. PostgreSQL apporte une transparence appréciée, avec des outils natifs pour comprendre l’exécution et une grande flexibilité.
Dans Atelier Nova, une promotion éclair provoque une montée soudaine des lectures de données. Le SGBD doit absorber le pic : si les index sont absents, la charge explose. Si l’architecture est saine, la performance reste stable et l’expérience d’achat reste fluide. Ici, l’insight est opérationnel : l’optimisation est une discipline continue, pas un “projet de fin”.
Besoin | Réponse côté SGBD | Impact sur les données |
|---|---|---|
Accès rapide | Index, cache, plans | Moins de lectures, réponses plus régulières |
Fiabilité | Journalisation, contrôle de concurrence | Cohérence des données malgré la simultanéité |
Protection | Rôles, audit, chiffrement | Réduction des fuites et meilleure traçabilité |
Usages concrets des logiciels de base de données : entreprises, santé, finance et Big Data
Dans l’entreprise, les bases de données structurent l’activité : stocks, ventes, achats, support, RH. Une enseigne de distribution dépend de données d’inventaire à jour pour éviter les ruptures et les surpromesses. Un CRM s’appuie sur des données de contacts, d’historique et de consentement pour piloter la relation client sans s’exposer.
Dans la finance, les données sont sensibles et le temps compte. Les paiements et la détection de fraude exigent des écritures rapides et des transactions irréprochables. Ici, une base de données solide est un filet de sécurité : un centime perdu à grande échelle devient un incident majeur, autant réglementaire que réputationnel.
Dans la santé, la confidentialité et la qualité priment. Les dossiers patients rassemblent des données hétérogènes (examens, imagerie, prescriptions) et imposent une gestion stricte des droits, car les utilisateurs n’ont pas tous la même légitimité. Les bases de données doivent aussi faciliter l’interopérabilité pour éviter les soins fragmentés.
En recherche et en industrie, les plateformes de Big Data exploitent des données massives : capteurs, logs, clickstream, simulations. On stocke, on nettoie, puis on alimente l’analyse et l’IA. Atelier Nova utilise ses données de retours et de délais transport pour prédire les ruptures, et transformer une contrainte logistique en avantage commercial.
Ce qui relie ces secteurs, c’est la capacité des bases de données à accélérer la décision. Quand les données sont fiables, les tableaux de bord et les applications automatisent des choix autrefois manuels. L’insight final : une bonne gestion des données est un investissement opérationnel, pas seulement informatique.
Bases de données cloud et cloud-native : scalabilité, disponibilité et réduction des coûts
Le passage au cloud change la manière de consommer des bases de données. Au lieu d’acheter des serveurs, on utilise un service : capacité adaptable, mises à jour automatisées, sauvegardes gérées, et réplication facilitée. Pour une équipe produit, c’est souvent la différence entre livrer une fonctionnalité en semaines ou en mois.
Les approches cloud-native sont pensées pour l’élasticité : montée en charge automatique, découplage du calcul et du stockage, tolérance aux pannes intégrée. Cette logique améliore la disponibilité : un incident matériel ne signifie plus forcément interruption. Pour des applications e‑commerce, l’enjeu est immédiat : chaque minute d’arrêt coûte en ventes et en confiance.
La scalabilité dans le cloud s’exprime aussi dans la gestion quotidienne. On peut créer des environnements de test à la demande, dupliquer une base de données pour simuler une migration, ou restaurer des données à un instant T. Cette agilité transforme la relation au risque : on expérimente davantage, car le retour arrière est plus simple.
Côté coûts, les modèles à l’usage sont attractifs, surtout pour les PME. Les bases de données open source comme MySQL ou PostgreSQL s’alignent très bien avec ces offres : on profite d’un moteur éprouvé et d’une facturation flexible dans le cloud. Mais la discipline reste nécessaire : des environnements oubliés ou des données dupliquées sans gouvernance finissent par gonfler la facture.
Pour Atelier Nova, l’objectif est double : absorber les pics saisonniers et réduire la charge d’exploitation. L’insight final : le cloud simplifie l’infrastructure, mais exige une gestion plus fine de l’architecture et des coûts.
Comparaison entre bases sur site, cloud traditionnelles et DBaaS
Les bases de données sur site (on‑premise) offrent un contrôle maximal : choix du matériel, réseau dédié, politiques internes strictes. Elles conviennent aux organisations avec contraintes fortes, ou à des environnements déjà amortis. En contrepartie, la gestion du cycle de vie (patching, sauvegardes, capacity planning) repose sur les équipes.
Les bases de données dans le cloud “traditionnel” consistent souvent à héberger un serveur dans une VM. On gagne en vitesse de déploiement et en flexibilité, mais on garde une grande partie de la maintenance. Le modèle DBaaS va plus loin : le fournisseur gère une large part de l’exploitation, et l’équipe se concentre sur les schémas, les données et les requêtes.
Dans Atelier Nova, une phase pilote garde une base de données sur site pour l’ERP historique, tandis que les nouveaux services partent en DBaaS. Ce schéma hybride illustre une réalité : les bases de données migrent rarement d’un bloc, elles se déplacent par lots, selon la valeur et le risque.
Modèle | Points forts | Points d’attention |
|---|---|---|
Sur site | Contrôle total, latence interne maîtrisée | Coûts initiaux, maintenance, capacité rigide |
Cloud (VM) | Déploiement rapide, flexibilité infra | Vous gérez encore patching et sauvegardes |
DBaaS | Automatisation, haute disponibilité, scalabilité | Dépendance fournisseur, gouvernance et coûts à surveiller |
Pour choisir, on compare aussi l’écosystème. Un service managé compatible MySQL simplifie la migration d’applications web, tandis qu’un environnement orienté Oracle convient mieux à des workloads historiques. L’insight final : la bonne option n’est pas la plus moderne, mais celle qui tient vos données et vos engagements opérationnels.
Le rôle stratégique des administrateurs de bases de données (DBA) : sécurité et maintenance
Le DBA n’est pas un gardien de serveurs : c’est le responsable de la santé des bases de données au quotidien. Il configure, surveille, planifie les sauvegardes, teste les restaurations, et ajuste les paramètres pour maintenir un niveau de service constant. Dans les organisations matures, il formalise aussi la gestion des changements : un index ajouté au bon endroit peut sauver une période de forte activité.
La dimension humaine est centrale. Le DBA forme les équipes à écrire des requêtes plus propres, à éviter les antipatterns, et à comprendre l’impact d’un schéma mal pensé sur la charge. Dans Atelier Nova, un atelier interne apprend aux développeurs à lire un plan d’exécution SQL : l’objectif n’est pas de les transformer en experts, mais de réduire les erreurs coûteuses sur des données critiques.
La sécurité fait aussi partie de la mission : rotation des secrets, principe du moindre privilège, masquage de données sensibles en environnements non‑prod. Avec l’essor du cloud, le DBA travaille davantage avec les équipes plateforme : réseau, IAM, chiffrement, politiques de logs. L’insight final : une base de données fiable dépend autant des personnes et des procédures que du logiciel.
Enjeux actuels des bases de données face à l’IA et aux données massives : conformité et sécurité
L’IA amplifie la valeur des données, mais aussi les risques. Plus on centralise et croise des données, plus la conformité (RGPD, exigences sectorielles, conservation) devient structurante. La question n’est plus seulement “peut-on stocker ?”, mais “a-t-on le droit, pour combien de temps, et avec quelle traçabilité ?”.
Les bases de données modernes doivent intégrer la gouvernance : catalogues, lignage, classification, politiques d’accès. Dans un scénario concret, Atelier Nova veut entraîner un modèle de recommandation avec des données d’achats. Il faut prouver le consentement, anonymiser certains champs, et documenter les transformations, sinon l’initiative IA se transforme en risque juridique.
La montée des volumes crée un autre défi : la qualité. Des données incomplètes, dupliquées ou incohérentes dégradent les modèles et les décisions. On voit réapparaître une exigence presque “artisanale” : définir des référentiels, imposer des validations, et mesurer la dérive. Le système technique doit aider, mais la gestion de la qualité est d’abord une discipline d’entreprise.
Sur la protection, la surface d’attaque s’élargit avec le cloud et les multiples services connectés. Il devient crucial d’isoler les environnements, de chiffrer les données au repos et en transit, et de journaliser les accès. L’insight final : à l’ère de l’IA, les données ne sont pas seulement un actif, ce sont aussi une responsabilité.
Tendances technologiques : IA pour l’automatisation, architectures distribuées et bases vectorielles
La première tendance forte est l’automatisation par IA des opérations de bases de données. Les outils aident à détecter des anomalies, proposer des index, anticiper une saturation, ou recommander des réglages. Dans un environnement cloud, ces mécanismes s’intègrent souvent nativement, réduisant la charge de maintenance tout en améliorant la stabilité.
La deuxième tendance est l’architecture hybride et distribuée : on combine plusieurs bases de données selon les charges, parfois entre sur site et cloud. Cette approche s’aligne sur la réalité des entreprises : certaines données restent près des systèmes historiques, tandis que de nouveaux produits s’exécutent dans le cloud. On parle moins de migration “tout ou rien” et plus de trajectoire.
La troisième tendance concerne les bases de données vectorielles, devenues centrales pour la recherche sémantique et les assistants IA. Elles stockent des représentations mathématiques (vecteurs) de textes, images ou sons afin de retrouver des données “proches” en sens plutôt qu’identiques en mots. Pour un service client, cela change tout : on retrouve des réponses pertinentes même si la question n’emploie pas les mêmes termes.
Ces nouveautés ne remplacent pas le relationnel ni le NoSQL : elles les complètent. La plupart des entreprises conservent une base de données relationnelle pour les écritures critiques, et ajoutent d’autres moteurs pour enrichir l’expérience IA. L’insight final : le futur se joue dans l’orchestration de plusieurs bases de données, pas dans la quête d’un outil unique.
Intégration de l’IA et importance croissante des bases orientées agents
Avec les assistants d’entreprise, les “agents” logiciels enchaînent des étapes : chercher des données, vérifier une règle, déclencher une action, puis consigner le résultat. Cela demande des bases de données capables de supporter à la fois le transactionnel et des accès plus exploratoires. Un agent peut lancer des requêtes SQL, consulter un index vectoriel, puis écrire un statut dans une base de données opérationnelle.
Dans Atelier Nova, un agent interne gère les litiges : il récupère les données de commande, compare les données de transport, extrait un échange client, puis propose une résolution. Pour éviter les erreurs, l’agent doit travailler sur des données gouvernées, et ses actions doivent être traçables dans le système. Une automatisation non auditée crée un risque pire que la lenteur.
Cette évolution renforce la nécessité de critères de choix clairs pour un logiciel et une stratégie de bases de données. Il faut évaluer le volume de données, la complexité (schéma stable ou variable), le temps de réponse attendu, le nombre d’utilisateurs, la scalabilité souhaitée, la tolérance aux pannes, l’intégration aux applications, et le budget. On ajoute désormais un point : la compatibilité avec des flux IA (vectorisation, traçabilité, politiques d’accès).
Concrètement, une entreprise peut garder Oracle pour le cœur financier, utiliser MySQL pour des services web, adopter du NoSQL pour des événements, et connecter une brique vectorielle pour la recherche sémantique. Cette coexistence est saine si la gestion des données (catalogue, qualité, sécurité) reste cohérente. L’insight final : l’IA pousse à penser “plateforme de données”, pas seulement “moteur de base de données”.
Repères pratiques pour choisir une solution (exemples concrets, à adapter) :
Si vos écritures doivent être strictes et auditables : une base de données relationnelle avec SQL et des transactions robustes (ex. Oracle, PostgreSQL).
Si vos données changent souvent de forme et que l’échelle prime : des bases de données NoSQL (documents, colonnes) avec une gouvernance claire.
Si vous visez un déploiement rapide et une maintenance réduite : DBaaS dans le cloud (souvent compatible MySQL), en surveillant coûts et conformité.
Les solutions open source et gratuites gardent une place majeure : elles réduisent le ticket d’entrée et favorisent l’expérimentation, ce qui est crucial pour des PME. Le cloud renforce cette démocratisation via le paiement à l’usage : on teste, on mesure, on ajuste sans immobiliser des budgets lourds. L’insight final : l’accès aux technologies avancées dépend moins de la taille de l’entreprise que de sa discipline sur les données.
Quelle différence entre une base de données et un SGBD ?
Une base de données est l’ensemble organisé de données (tables, enregistrements, index). Un SGBD est le système logiciel qui permet la gestion : créer les structures, exécuter les requêtes SQL, sécuriser l’accès, gérer les transactions et assurer la maintenance.
Quand choisir une base relationnelle plutôt que NoSQL ?
Choisissez une base relationnelle lorsque vos données sont très structurées, que l’intégrité et les transactions sont critiques (facturation, paiements, ERP) et que SQL est central. Choisissez NoSQL lorsque la flexibilité du schéma, l’échelle horizontale ou des modèles spécifiques (document, colonne, graphe) sont plus adaptés aux données et aux applications.
Le cloud est-il toujours moins cher pour les bases de données ?
Le cloud réduit souvent les coûts initiaux et la charge de gestion, mais il peut devenir coûteux si les données sont dupliquées, si les environnements tournent inutilement ou si les requêtes ne sont pas optimisées. Le gain se confirme avec une gouvernance des données, un suivi FinOps et une architecture adaptée.
Quels logiciels sont les plus connus sur le marché ?
Parmi les solutions propriétaires, Oracle est une référence historique pour les environnements critiques. Dans l’open source, MySQL et PostgreSQL sont largement adoptés. Pour l’analytique à grande échelle, Teradata est un acteur reconnu. Le bon choix dépend surtout de vos données, de vos contraintes et de votre écosystème applicatif.
Comment préparer des bases de données pour des usages IA (recherche sémantique, agents) ?
Il faut gouverner les données (qualité, droits, traçabilité), définir les sources fiables, puis ajouter les briques nécessaires : pipelines de préparation, éventuellement base vectorielle pour la similarité, et mécanismes d’audit. L’objectif est de permettre à des agents de lire et écrire des données dans un système contrôlé, sans compromettre la conformité.