

Fonctionnalités clés du logiciel OCR gratuit FreeOCR sous Windows
Conversion d’images et PDF scannés en texte modifiable
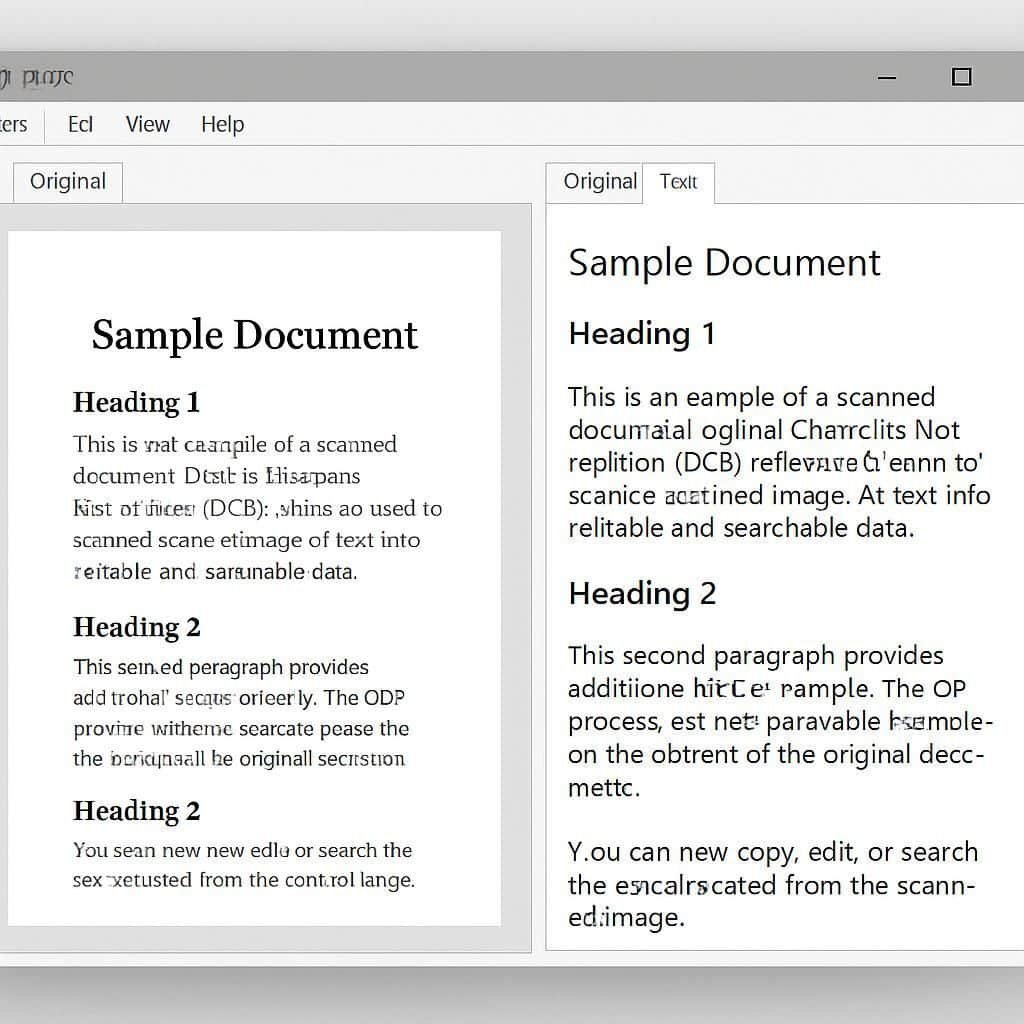
Avec FreeOCR, le point fort est la conversion rapide d’une image ou d’un PDF issu d’un scan en texte exploitable. Dans un service RH fictif, “Atelier Lemaire”, une assistante traite chaque semaine des dossiers papier : en important un PDF scanné, elle obtient un texte prêt à être corrigé, copié, ou archivé sans ressaisie.
Le flux est simple : on charge un fichier (un fichier image ou un PDF), on lance l’OCR, puis on récupère le texte. Cette logique réduit les erreurs humaines et accélère la préparation d’un document administratif, ce qui reste un avantage concret quand on doit répondre vite à un audit.
Utilisation du moteur Tesseract OCR pour une reconnaissance fiable
FreeOCR s’appuie sur Tesseract OCR, un moteur connu pour sa robustesse sur de nombreux alphabets et polices. Cette base technique rend l’OCR crédible pour transformer un PDF scanné en texte, même si la mise en page n’est pas parfaite.
Dans la pratique, l’analyse repère les zones de caractères, les segmente, puis recompose un texte cohérent. Sur un vieux courrier imprimé, l’OCR peut confondre un “O” et un “0” si l’encre est pâle ; l’astuce est d’améliorer la qualité du scan pour rendre la reconnaissance optique plus stable. L’idée clé : le moteur fait beaucoup, mais la source compte autant.
Prise en charge des documents multi-pages
Un besoin récurrent en entreprise consiste à traiter un dossier de 20 pages en un seul PDF. FreeOCR gère les PDF multi-pages et permet de choisir les pages à traiter, ce qui limite la perte de temps lorsque seules 3 pages contiennent du texte utile pour l’extraction.
Dans “Atelier Lemaire”, un classeur numérisé contient des annexes inutiles : sélectionner une plage de pages évite une analyse globale trop longue. Au final, on garde un texte plus propre, plus proche du besoin réel, et l’OCR devient un outil de tri autant que de transcription.
Compatibilité avec divers formats d’images (PNG, JPG, TIFF)
La compatibilité avec PNG, JPG et TIFF apporte de la souplesse quand les sources varient : photo de téléphone, export de scanner, copie d’écran. Pour un particulier, cela signifie convertir une image de facture en texte sans la réimprimer ; pour un service archives, cela signifie conserver un TIFF haute qualité et produire un PDF ou un texte en parallèle.
Le choix du type d’image influence l’OCR : une image compressée en JPG peut introduire du bruit, tandis qu’un TIFF peut préserver les détails des caractères. Ce petit arbitrage technique fait souvent la différence entre un texte immédiatement réutilisable et un texte à corriger ligne par ligne.
Compatibilité Twain : connexion directe des scanners avec FreeOCR
Capture en temps réel et conversion sans étape intermédiaire
La compatibilité Twain permet de relier directement un scanner à FreeOCR sous Windows. Au lieu de scanner vers un fichier puis de l’ouvrir, on capture et on lance l’OCR presque dans le même geste, ce qui fluidifie la conversion et diminue les manipulations.
Dans un bureau d’accueil, cela change le quotidien : on numériser un justificatif, on obtient le texte, puis on le colle dans un document interne. Cette chaîne courte évite aussi la multiplication de fichier temporaires sur le poste, un détail qui compte quand on veut garder une arborescence propre.
Avantages pour les professionnels de la numérisation administrative
Pour des lots de dossiers, Twain + OCR donne un vrai gain de temps : moins d’allers-retours entre applications et moins de risques d’importer le mauvais PDF. Une petite mairie fictive, “Saint-Rivière”, traite des demandes papier : la saisie manuelle était lente, alors que l’OCR permet une extraction rapide des noms, adresses et références.
Le bénéfice n’est pas seulement la vitesse : c’est la traçabilité. On peut conserver le PDF scanné comme preuve et stocker le texte dans un fichier séparé pour la recherche interne, ce qui facilite la consultation d’un document des mois plus tard. Prochaine étape logique : choisir un bon format d’export pour les équipes.
Options d’export et formats supportés pour les textes reconnus
Sauvegarde en RTF, Word (.docx) et TXT pour une réutilisation facile
Après l’OCR, l’export est crucial : FreeOCR peut sauvegarder le texte en RTF, en TXT, ou vers un fichier compatible Word (.docx) selon les besoins. Dans un cabinet comptable, un PDF de relevé est transformé en texte puis exporté vers Word pour ajouter des commentaires et préparer un courrier client.
Dans la vraie vie, on alterne souvent : TXT pour du texte brut, RTF pour conserver un minimum de mise en forme, et Word quand on doit relire et mettre en page. Cette variété évite d’être enfermé dans un seul fichier et rend l’OCR utile à tous les profils, du juriste à l’étudiant.
Faciliter le traitement et le partage des documents numérisés
Partager un PDF scanné, c’est bien ; partager le texte qui en sort, c’est souvent mieux. Une fois le texte produit, il devient indexable, recherchable, et copiable dans un email ou un outil de gestion. Pour une équipe projet, coller un extrait dans Microsoft Word permet de citer une clause, puis de l’annoter sans repartir du scan.
Ce passage du PDF figé à un texte vivant simplifie aussi la collaboration : on évite de demander “tu peux retaper le paragraphe page 4 ?”. En pratique, l’OCR transforme le document en matière première, plus facile à exploiter et à distribuer.
Sortie | Quand l’utiliser | Atout principal |
|---|---|---|
TXT | Notes, scripts, import base de données | texte léger, compatible partout |
RTF | Compte rendu simple avec mise en forme | Conserve une structure minimale |
Word (.docx) | Rapports, courriers, relecture | Facilite corrections et partage bureautique |
Gratuité et simplicité d’utilisation : un logiciel OCR autonome et sécurisé
Installation locale sans création de compte ni abonnement
Le caractère gratuit et “standalone” est un argument fort : FreeOCR s’installe sur Windows sans compte, sans abonnement, sans dépendre d’un site tiers. Pour un indépendant, cela évite les démarches et permet de lancer un OCR à tout moment, même hors connexion.
Le téléchargement d’un logiciel local répond aussi à un besoin de continuité : pas de quota de pages, pas de limite liée à un service distant. Ce fonctionnement direct simplifie l’adoption par des équipes non techniques, et réduit la friction entre le scan d’un PDF et le texte final.
Confidentialité et sécurité garanties sans service en ligne
Traiter des bulletins de salaire, des pièces d’identité ou des contrats dans un outil en ligne peut poser problème. Avec FreeOCR, le PDF, l’image et le texte restent sur la machine, ce qui protège la vie privée et limite l’exposition des données.
Côté sécurité, un téléchargement sérieux passe par une source fiable et un contrôle antivirus. Le fait que l’OCR fonctionne localement réduit aussi les risques d’interception pendant l’upload, un point souvent décisif pour des documents sensibles. Et quand la confidentialité est maîtrisée, on peut ensuite regarder lucidement les limites et les alternatives.
Tableau comparatif OCR (gratuit) — Windows
Comparez en un coup d’œil FreeOCR, une solution OCR en ligne et un outil OCR multiplateforme. Filtrez selon vos priorités et obtenez une recommandation par profil.
Filtres rapides
Activez les critères importants pour vous. Le tableau se met à jour et un score indicatif est calculé.
Recommandation par profil
Choisissez votre profil pour obtenir un choix conseillé et une explication.
—
Conseil rapide (avant de choisir)
Si vos documents contiennent des données sensibles (identité, factures, dossiers), privilégiez un OCR qui fonctionne en local. Pour des lots de scans, la prise en charge PDF multi-pages et l’export (DOCX) font gagner beaucoup de temps.
Comparateur
Cliquez sur un logiciel pour voir ses détails. Les scores sont indicatifs (selon vos filtres).
| Logiciel / Service | Confidentialité (local) | Installation | PDF multi-pages | Export Word / DOCX | Support TWAIN | Coût | Score | Actions |
|---|
Fiche détaillée
Sélectionnez une ligne du tableau pour afficher les points forts et limites.
Mini-aide au choix (2 questions)
Répondez et on vous suggère l’option la plus adaptée.
Limites du logiciel FreeOCR et alternatives gratuites ou payantes
Interface utilisateur vieillissante et précision variable selon la qualité
La principale critique vise l’interface : elle paraît datée et moins guidée que certains outils modernes. L’OCR peut aussi être inégal sur un PDF sombre, une image floue ou un texte très stylisé, ce qui impose une relecture, surtout avant d’envoyer un courrier Word.
Dans un cas concret, une photo de ticket prise de travers produit un texte avec des sauts de ligne erratiques. En améliorant la prise de vue et en rescannant, on obtient un texte éditable plus propre, preuve que la qualité d’entrée reste la variable dominante.
Exclusivité Windows et absence de versions macOS ou Linux
FreeOCR reste centré sur Windows, ce qui exclut macOS et Linux. Pour une équipe mixte, cela peut compliquer la standardisation : le même PDF ne sera pas traité avec le même logiciel sur tous les postes.
Dans ce contexte, certains choisissent un workflow hybride : Windows au bureau pour l’OCR local, et une solution alternative à la maison. Ce choix dépend du niveau d’exigence sur la confidentialité, le volume de PDF à traiter, et la nécessité d’exporter vers Word.
Alternatives en ligne ou multiplateformes adaptées à d’autres besoins
Quand on cherche une expérience plus moderne, des services OCR en ligne permettent une conversion rapide sans installation, parfois avec détection multi-langues. Ils sont pratiques pour un PDF ponctuel, mais ils posent des questions de confidentialité et de volumétrie, surtout si l’on traite beaucoup d’images.
En local, on peut associer un outil de scan comme NAPS2 (souvent apprécié pour piloter la numérisation) avec un moteur d’OCR selon le poste. Le bon choix dépend du type de fichier, du besoin d’export vers Word, et de la sensibilité du document. Dans tous les cas, optimiser la source reste la méthode la plus rentable.
Optimiser l’utilisation du logiciel OCR gratuit FreeOCR : conseils et cas d’usage
Paramètres d’image recommandés pour une reconnaissance optimale
Pour améliorer l’OCR, la règle simple est d’augmenter la qualité avant tout : viser 200 DPI minimum (300 DPI si le texte est petit) et éviter les ombres. Une image trop compressée ou un PDF trop “léger” dégrade la reconnaissance optique et multiplie les corrections dans Word.
Il aide aussi de redresser la page et d’améliorer le contraste : un scan propre donne un texte plus fidèle. Ce temps investi en amont se récupère vite, car la relecture après OCR coûte beaucoup plus cher que refaire un bon scan.
Configuration technique requise et compatibilité scanner Twain
Sur Windows, l’usage est plus fluide quand le pilote Twain du scanner est à jour. Un scanner de bureau classique suffit, mais la stabilité du driver conditionne la capture : un mauvais pilote peut générer un fichier incomplet ou un PDF corrompu, ce qui bloque ensuite l’OCR.
Concernant le téléchargement du logiciel, privilégier une source reconnue et vérifier le fichier avant installation limite les risques. Une fois installé, l’outil reste léger : pour des lots de PDF, un PC récent améliore la vitesse, mais l’essentiel demeure la qualité d’image et la bonne configuration Twain.
Type de source | Réglage conseillé | Impact sur le texte |
|---|---|---|
PDF scanné (administratif) | 300 DPI, noir & blanc ou niveaux de gris | texte plus net, moins d’erreurs OCR |
image photo (smartphone) | Bonne lumière, page à plat, recadrage | Moins de distorsion, meilleur alignement du texte |
TIFF archive | Contraste élevé, conservation sans compression | Base idéale pour OCR et archivage |
Cas d’usage typiques pour particuliers et professionnels
L’OCR avec FreeOCR sert autant à l’archivage qu’à la productivité. Un étudiant peut transformer un PDF de polycopié en texte pour faire des recherches par mots-clés ; un artisan peut convertir une image de devis en fichier Word afin de réutiliser un modèle sans tout retaper.
Pour les équipes administratives, le duo scan + OCR aide à structurer l’information : adresses, références, dates deviennent du texte copiable dans un tableur ou un ERP. Ce passage du papier au fichier réduit les erreurs, et accélère la préparation de réponses standardisées dans Word.
Conversion de livres numérisés en documents textuels modifiables
Numériser un ouvrage ancien en PDF est une première étape ; l’OCR permet ensuite d’obtenir un texte exploitable pour citer, annoter, ou préparer une réédition. Dans une association culturelle, un bénévole scanne des brochures locales : FreeOCR transforme le PDF en texte puis en Word pour corriger les coquilles et harmoniser la mise en page.
Ce scénario illustre un point : la conversion n’est pas qu’un gadget, c’est une passerelle entre archives papier et travail éditorial. Même si le résultat demande une relecture, on gagne des heures par rapport à une saisie complète.
Extraction rapide de données pour études et analyse documentaire
Pour une étude, extraire des passages depuis un PDF scanné évite de recopier des pages entières. Une doctorante en sciences sociales collecte des coupures de presse en image : l’OCR produit du texte qu’elle peut indexer, comparer et citer, puis organiser dans des dossiers par fichier.
Cette méthode accélère l’analyse thématique et aide à repérer des occurrences d’un terme dans un ensemble de PDF. L’insight pratique : plus le corpus est volumineux, plus l’OCR devient une stratégie de recherche, pas seulement une conversion.
Sécurité du téléchargement et respect de la vie privée des utilisateurs
Pour rester serein, il faut traiter l’OCR comme un outil de production : on sécurise le téléchargement, on scanne le fichier d’installation, puis on garde les PDF et images dans un dossier maîtrisé. Le caractère gratuit de FreeOCR ne doit pas conduire à négliger les bonnes pratiques de poste de travail.
La confidentialité est un avantage structurel : les PDF, le texte et chaque fichier restent en local, ce qui évite l’envoi à un service tiers. C’est souvent la raison décisive de choisir ce logiciel sur Windows, surtout quand la langue du document est spécifique et que l’on veut garder la main sur les données.
FreeOCR peut-il transformer un PDF scanné en fichier Word ?
Oui : après OCR, vous pouvez enregistrer le texte dans un format compatible Word (.docx) afin de l’ouvrir et le corriger dans Word. Gardez le PDF original pour référence, puis travaillez sur le texte exporté pour la mise en page.
Quelle résolution choisir pour améliorer la précision OCR sur des images ?
Visez au moins 200 DPI, et plutôt 300 DPI si le texte est petit. Une image bien contrastée, droite et sans ombre donne un texte plus fiable, ce qui réduit les corrections dans Word ou dans un autre logiciel.
FreeOCR gère-t-il les PDF multi-pages et la sélection de pages ?
Oui : vous pouvez traiter des PDF multi-pages et, selon le besoin, sélectionner une plage de pages. C’est utile pour extraire du texte uniquement là où l’information se trouve, sans analyser tout le document.
Pourquoi privilégier un OCR local gratuit plutôt qu’un service en ligne ?
Un OCR local évite d’envoyer un PDF ou une image vers un serveur, ce qui protège la vie privée. Il supprime aussi les limites de volumétrie de certains services en ligne, tout en gardant une conversion accessible et gratuite sur Windows.